Apa Itu Multi-Head Latent Attention (MLA)? Rahasia Efisiensi DeepSeek
Dunia Artificial Intelligence (AI) belakangan ini sedang ramai membicarakan sebuah pergeseran besar. Jika sebelumnya kompetisi antar pengembang AI hanya berfokus pada siapa yang paling “pintar”, kini fokus tersebut meluas ke arah efisiensi.
Kemunculan model-model terbaru, seperti DeepSeek, yang mampu menyamai performa model closed-source raksasa namun dengan biaya operasional yang jauh lebih rendah, memicu tanda tanya besar di kalangan komunitas teknologi: apa rahasianya?
Jawabannya bukan hanya pada data pelatihan yang lebih banyak, melainkan pada inovasi arsitektur di balik layar. Salah satu tantangan terbesar dalam menjalankan Large Language Models (LLM) adalah manajemen memori.
Saat kita berinteraksi dengan AI dalam konteks yang panjang misalnya menganalisis dokumen tebal atau coding yang kompleks model membutuhkan kapasitas memori atau VRAM yang sangat besar untuk “mengingat” informasi sebelumnya. Dalam istilah teknis, hambatan ini sering terjadi pada pembengkakan Key-Value (KV) Cache.
Di sinilah Multi-Head Latent Attention (MLA) hadir sebagai solusi yang revolusioner.
MLA adalah sebuah teknik arsitektur baru yang dirancang untuk memecahkan masalah inefisiensi pada memori inference.
Berbeda dengan metode tradisional seperti Multi-Head Attention (MHA) yang cenderung boros sumber daya, atau Grouped-Query Attention (GQA) yang mencoba berhemat namun terkadang mengurangi detail, MLA menawarkan jalan tengah yang brilian.
Teknologi ini memungkinkan model AI untuk melakukan kompresi data ingatan secara ekstrem tanpa mengorbankan akurasi atau kecerdasan model tersebut.
Dalam artikel ini, kita akan membedah konsep Multi-Head Latent Attention dengan bahasa yang mudah dipahami.
Kita akan melihat bagaimana teknologi ini bekerja mengubah cara AI “berpikir”, dan mengapa MLA dianggap sebagai kunci masa depan untuk generative AI yang lebih cepat, murah, dan bisa diakses oleh siapa saja.
Apa Itu Multi-Head Latent Attention (MLA)?
Secara sederhana, Multi-Head Latent Attention (MLA) adalah sebuah teknik arsitektur jaringan saraf (neural network) yang dirancang untuk mengoptimalkan cara AI menyimpan dan memproses informasi.
Jika kita menganggap AI sebagai sebuah otak raksasa, MLA adalah metode pengarsipan super efisien yang membuat otak tersebut tidak cepat “penuh” atau overload saat memproses data dalam jumlah besar.
Teknologi ini pertama kali diperkenalkan dan dipopulerkan oleh DeepSeek dalam model seri V2 dan V3 mereka.
Tujuannya spesifik adalah mengatasi kelemahan utama model bahasa tradisional yang sangat boros memori saat melakukan percakapan panjang atau memproses dokumen tebal.
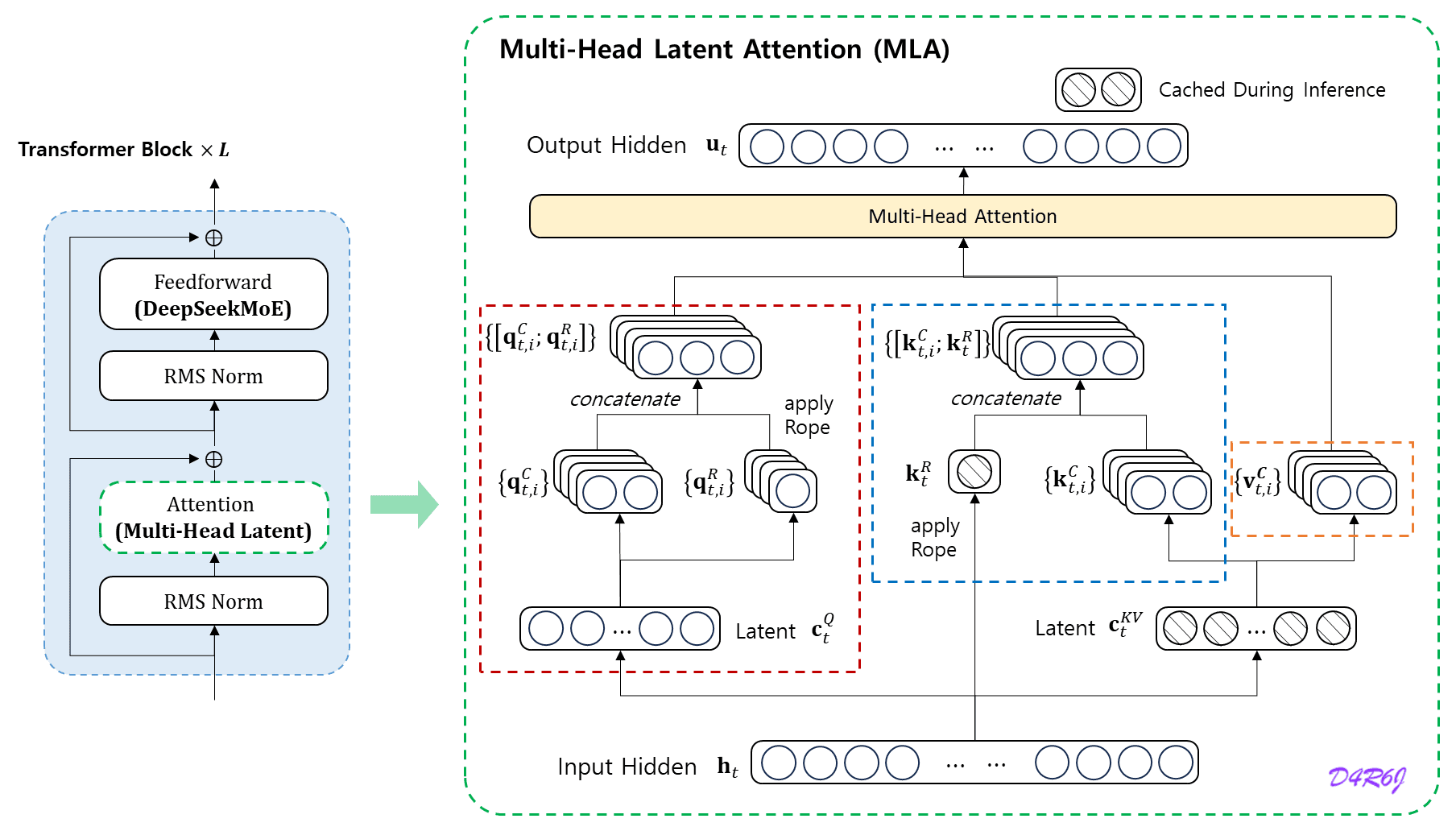
Dalam istilah teknis, MLA menggantikan mekanisme standar yang disebut Key-Value (KV) Cache dengan sistem yang jauh lebih ringkas menggunakan teknik kompresi canggih yang disebut Low-Rank Key-Value Joint Compression.
Bagaimana Cara Kerja MLA?
Untuk memahami kejeniusan di balik MLA, mari kita gunakan analogi sebuah Perpustakaan Koki.
Bayangkan sebuah model AI adalah seorang Kepala Koki yang harus mengingat ribuan resep masakan (data/konteks) yang dipesan oleh pelanggan.
1. Cara Lama (Multi-Head Attention / MHA)
Dalam sistem lama, Koki harus menyimpan setiap piring masakan yang sudah jadi di meja dapur agar siap sewaktu-waktu dicicipi kembali.
- Masalahnya: Meja dapur (Memory/VRAM) sangat terbatas. Jika ada 1.000 pesanan, meja akan penuh sesak. Koki jadi lambat bergerak, dan restoran harus menyewa meja tambahan yang sangat mahal (High Cost).
2. Cara Baru dengan MLA
Dengan MLA, Koki tidak menyimpan piring makanannya. Sebaliknya, ia hanya menyimpan kartu resep inti (Master Recipe) yang ditulis dalam kode singkatan yang sangat padat.
- Konsep Latent: Istilah Latent di sini berarti “tersembunyi” atau “berpotensi”. Kartu resep itu bukan makanannya, tapi menyimpan potensi untuk menciptakan kembali rasa makanan tersebut dengan akurasi 100% saat dibutuhkan.
- Prosesnya: Saat ada pertanyaan dari pelanggan, Koki mengambil kartu resep kecil itu, dan secara instan “mengembangkan” (decompress) informasinya menjadi rasa yang utuh.
- Hasilnya: Meja dapur tetap lega karena hanya berisi tumpukan kartu kertas, bukan ribuan piring. AI bisa mengingat konteks pembicaraan yang sangat panjang (seperti novel ratusan halaman) tanpa kehabisan memori.
Rahasia Dapur MLA: Kompresi Tanpa Hilang Detail
Mungkin kamu bertanya, “Kalau datanya dikompres, apakah AI-nya jadi pikun atau kurang pintar?”
Di sinilah letak keunggulan MLA. Berbeda dengan metode penghematan lain seperti Grouped-Query Attention (GQA) yang terkadang harus “membuang” sedikit detail demi hemat memori, MLA menggunakan pendekatan matematika yang disebut Low-Rank Joint Compression.
Bayangkan file .zip di komputer kamu. Saat kamu mengompres file dokumen besar menjadi .zip, ukurannya menyusut drastis.
Namun, saat diekstrak kembali, isinya tetap utuh tanpa ada satu huruf pun yang hilang. MLA bekerja dengan prinsip serupa di dalam “otak” AI: ia memadatkan data Key dan Value menjadi vektor laten yang kecil saat disimpan, dan memulihkannya kembali saat dibutuhkan untuk berpikir (inference).
Selain itu, MLA juga menerapkan trik pintar bernama Decoupled Rotary Positional Embedding (RoPE). Secara sederhana, ini adalah cara MLA memastikan urutan kata (misalnya: “Ibu makan” vs “Makan ibu”) tetap terjaga dengan sempurna, meskipun datanya sedang dikompresi habis-habisan.
Perbedaan MLA dengan MHA dan GQA
Untuk memahami mengapa Multi-Head Latent Attention (MLA) disebut sebagai teknologi masa depan, kita perlu melihat perbandingannya dengan teknologi pendahulunya. Perbedaan utamanya terletak pada bagaimana mereka mengelola “ingatan” atau memori saat AI sedang bekerja.
Berikut adalah perbandingan tiga generasi teknologi attention pada AI:
1. Multi-Head Attention (MHA): Standar Lama yang “Boros”
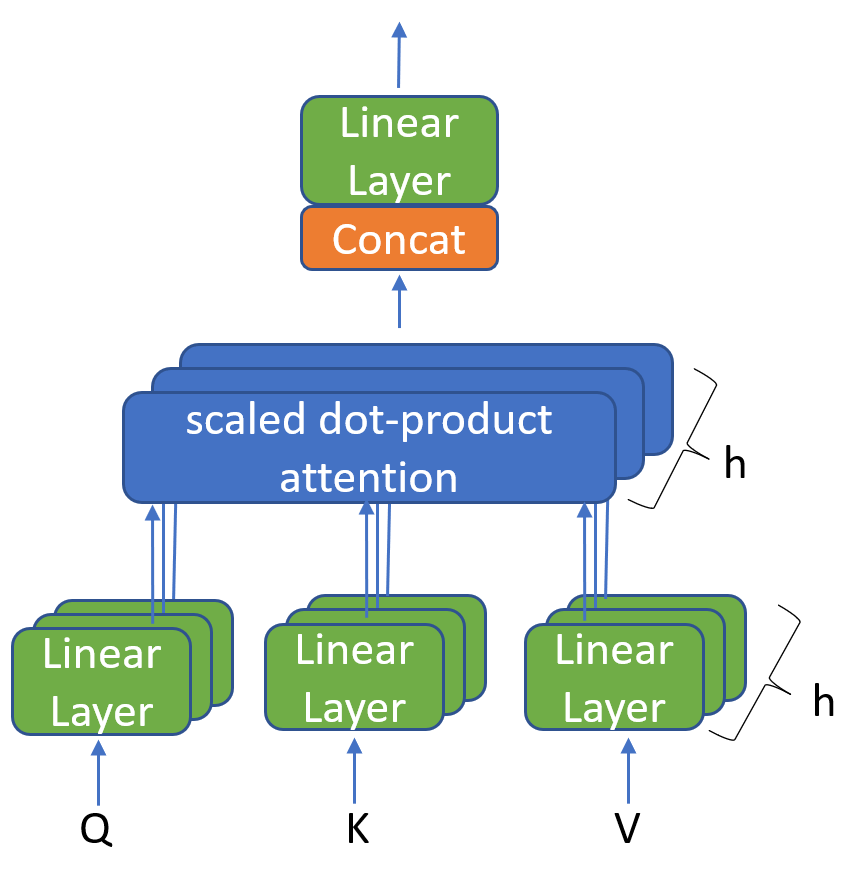
Ini adalah fondasi asli dari teknologi Transformer yang melahirkan revolusi AI seperti GPT-3 di masa-masa awal. MHA adalah “cara klasik” AI bekerja sebelum efisiensi menjadi isu utama.
- Cara Kerja (Mekanisme): Dalam arsitektur MHA, setiap unit pemroses atau “kepala” (head) beroperasi secara mandiri dan eksklusif.
Bayangkan sebuah kelas berisi 100 siswa cerdas. Dalam sistem MHA, setiap siswa wajib memegang satu buku ensiklopedia lengkap milik mereka sendiri. Mereka menolak untuk berbagi. Jadi, jika ada 100 siswa, sekolah harus menyediakan 100 rak buku besar.
Secara teknis, ini berarti untuk setiap Query Head (bagian yang bertanya/mencari konteks), sistem harus menyimpan pasangan Key dan Value (KV) yang unik secara utuh. Tidak ada penghematan, semuanya disimpan “mentah” apa adanya. - Kelebihan: Akurasi Tanpa Kompromi Karena setiap “kepala” memiliki akses penuh ke catatannya sendiri, kemampuan AI dalam menangkap nuansa bahasa sangatlah tinggi. Model ini sangat jeli melihat hubungan antar kata yang rumit tanpa ada detail yang hilang. Ini adalah alasan mengapa model lama sangat pintar, meskipun lambat.
- Kekurangan: “Mimpi Buruk” bagi Memori (KV Cache) Masalah muncul saat kita meminta AI memproses dokumen panjang (misalnya, menganalisis laporan keuangan 50 halaman).
- Boros VRAM: Karena setiap kepala menyimpan data terpisah, memori kartu grafis (VRAM) akan terisi penuh dengan sangat cepat oleh tumpukan data yang disebut KV Cache.
- Biaya Mahal & Lambat: Saat memori penuh, AI menjadi sangat lambat (high latency) dalam merespons. Untuk menjalankannya dengan lancar, dibutuhkan hardware server kelas atas yang harganya selangit, membuat biaya operasional menjadi tidak efisien.
2. Grouped-Query Attention (GQA)
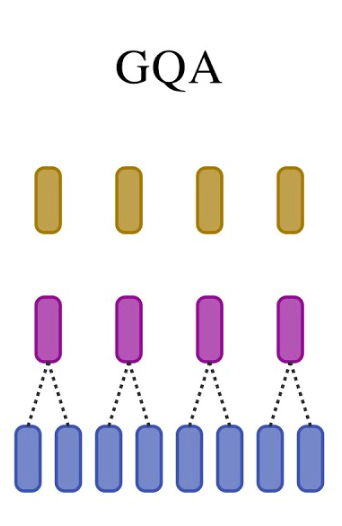
Jika MHA adalah standar kualitas, maka GQA adalah standar efisiensi yang mendominasi dunia open-source belakangan ini. Teknologi ini menjadi tulang punggung bagi model-model populer seperti Llama-2, Llama-3, hingga Mistral, karena berhasil menyeimbangkan performa dan biaya.
- Cara Kerja (Mekanisme): GQA hadir dengan filosofi “berbagi beban”. Alih-alih setiap kepala bekerja sendiri-sendiri, GQA mengelompokkan mereka.
Mari kembali ke analogi kelas tadi. Jika sebelumnya 100 siswa memegang 100 buku, dalam sistem GQA, siswa dibagi menjadi beberapa kelompok kecil (misalnya kelompok berisi 8 orang). Setiap kelompok hanya diberikan satu buku teks untuk dipakai bergantian.
Secara teknis, ini berarti beberapa Query Heads dipaksa untuk berbagi satu pasangan Key dan Value yang sama. Rasio penyimpanannya bukan lagi 1:1, melainkan bisa 8:1 atau lebih. - Kelebihan: Penghematan Memori yang Masif Dampaknya sangat terasa pada penggunaan VRAM. Dengan mengurangi jumlah data Key-Value yang harus disimpan, ukuran KV Cache menyusut drastis (bisa berkurang hingga 8x lipat atau lebih).
- Inference Lebih Cepat: Karena data yang harus dibaca lebih sedikit, AI bisa menjawab pertanyaan (inference) dengan jauh lebih ngebut.
- Aksesibilitas: Ini memungkinkan model-model canggih seperti Llama-3 bisa dijalankan di komputer dengan spesifikasi yang lebih rendah dibandingkan model lama.
- Kekurangan: Kualitas yang “Sedikit” Dikorbankan (Slightly Lossy) Namun, tidak ada makan siang gratis. Efisiensi ini datang dengan sedikit biaya pada kualitas.
- Nuansa yang Hilang: Karena harus “berbagi ingatan”, kemampuan AI untuk menangkap detail yang sangat spesifik atau nuansa halus kadang sedikit berkurang dibandingkan MHA.
- Kompromi: Meskipun begitu, penurunan kualitas ini seringkali dianggap sangat kecil dan masih bisa diterima (tolerable) demi mendapatkan kecepatan dan efisiensi yang jauh lebih baik.
3. Multi-Head Latent Attention (MLA)
Inilah inovasi mutakhir yang dipopulerkan oleh DeepSeek. Jika GQA adalah tentang “berbagi kekurangan” demi berhemat, MLA hadir dengan pendekatan radikal: Kompresi Cerdas.
Teknologi ini membuktikan bahwa kita tidak perlu mengorbankan kepintaran AI hanya untuk membuatnya lebih efisien.
- Cara Kerja (Mekanisme): MLA tidak memaksa kepala pemroses untuk berbagi ingatan seperti GQA. Sebaliknya, ia memadatkan data itu sendiri.
Kembali ke analogi kelas siswa tadi. Di sistem MLA, siswa tidak perlu membawa buku fisik yang tebal. Sebagai gantinya, setiap siswa hanya membawa secarik kertas kecil berisi kode (seperti QR Code).- Saat siswa membutuhkan informasi, mereka memindai kode tersebut.
- Secara ajaib (melalui proses matematika projection), kode kecil itu menerjemahkan dirinya kembali menjadi halaman informasi yang lengkap dan utuh.
- Secara teknis, MLA menggunakan teknik Low-Rank Key-Value Joint Compression. Data ingatan (KV Cache) yang biasanya memakan banyak ruang, dikompresi menjadi vektor laten yang sangat kecil saat disimpan, dan hanya “dimekarkan” kembali saat AI perlu menjawab pertanyaan.
- Kelebihan: Hemat Memori Tingkat Dewa Efisiensi yang ditawarkan MLA sangat luar biasa. Penggunaan memori (KV Cache) bisa ditekan hingga seminimal mungkin, bahkan seringkali lebih hemat daripada GQA.
- Konteks Super Panjang: Karena hemat tempat, kita bisa “menyuapi” AI dengan dokumen ribuan halaman (seperti satu buku novel penuh) tanpa membuat memori server meledak atau menjadi lambat.
- Biaya Murah: Inilah rahasia kenapa API model DeepSeek bisa sangat murah. Mereka membutuhkan jauh lebih sedikit hardware mahal untuk melayani jutaan pengguna.
- Kualitas: Cerdas Tanpa Kompromi (Setara MHA) Ini adalah keunggulan “mahal” yang dimiliki MLA. Tidak seperti GQA yang sedikit lossy (menurun kualitasnya), MLA mampu mempertahankan akurasi setara dengan MHA (standar lama yang boros).
- Karena proses kompresinya berbasis matriks low-rank yang presisi, hampir tidak ada informasi penting yang hilang. AI tetap bisa menangkap detail kecil dan nuansa bahasa yang rumit seolah-olah ia memiliki memori tak terbatas.
- Singkatnya: MLA memberikan kecepatan Ferrari dengan konsumsi bensin motor bebek.
Kenapa MLA Sangat Penting bagi Masa Depan AI?
Mungkin Anda bertanya, “Mengapa saya harus peduli dengan cara AI mengompres memori?” Jawabannya sederhana: Aksesibilitas.
Selama beberapa tahun terakhir, pengembangan Large Language Models (LLM) menghadapi tembok besar bernama “biaya”.
Semakin pintar sebuah AI, semakin besar memori (VRAM) yang dibutuhkan, dan semakin mahal harga operasionalnya.
Ini membuat AI level atas (state-of-the-art) hanya bisa dikuasai oleh perusahaan teknologi raksasa dengan modal triliunan.
Multi-Head Latent Attention (MLA) hadir meruntuhkan tembok tersebut. Berikut adalah tiga alasan mengapa teknologi ini krusial:
1. Memangkas Biaya Operasional secara Drastis (Cost Efficiency)
Biaya terbesar dalam menjalankan AI bukanlah listrik, melainkan pengadaan GPU cluster dengan kapasitas memori raksasa untuk menampung KV Cache.
Dampak MLA dengan mengompresi kebutuhan memori hingga titik terendah, MLA memungkinkan model AI yang sangat cerdas berjalan di atas infrastruktur hardware yang jauh lebih sedikit.
Inilah alasan mengapa penyedia layanan seperti DeepSeek bisa menawarkan harga API yang sangat murah bahkan jauh di bawah harga pasar kompetitornya tanpa membakar uang. Efisiensi arsitektur = harga yang lebih terjangkau bagi konsumen.
2. Menguasai “memory” Jangka Panjang (Long Context Mastery)
Salah satu keluhan pengguna AI adalah model yang sering “lupa” atau menjadi lambat ketika diajak berdiskusi tentang dokumen yang sangat panjang (misalnya: menganalisis laporan hukum setebal 500 halaman atau coding ribuan baris).
Masalah Lama: Pada model lama (MHA), semakin panjang teksnya, KV Cache akan membengkak hingga memori penuh (Out of Memory).
Karena jejak memorinya sangat kecil, MLA memungkinkan AI memiliki Context Window (jendela konteks) yang sangat masif.
AI bisa memproses satu buku novel utuh sekaligus dan menjawab pertanyaan tentang detail di halaman manapun dengan cepat, tanpa mengalami penurunan performa (latency) yang berarti.
3. Demokratisasi AI Canggih (Democratization)
Sebelum adanya teknik efisiensi seperti MLA, model dengan parameter ratusan miliar (seperti GPT-4 atau Claude 3 Opus) mustahil dijalankan oleh individu atau perusahaan kecil secara mandiri (self-hosted).
Masa Depan Berkat MLA, hambatan hardware menjadi lebih rendah. Di masa depan, teknologi ini membuka peluang bagi model-model AI “raksasa” untuk dijalankan di server lokal perusahaan menengah, atau bahkan pada workstation pribadi para pengembang, menjaga privasi data tetap aman tanpa bergantung pada cloud mahal.
Siapa yang Menggunakan Teknologi MLA?
Meskipun konsep efisiensi memori sudah lama diteliti, implementasi nyata dari Multi-Head Latent Attention (MLA) yang mengguncang dunia AI dipelopori oleh satu nama besar: DeepSeek.
1. DeepSeek
Perusahaan riset AI ini adalah aktor utama yang memperkenalkan dan mempopulerkan arsitektur MLA ke panggung global.
- DeepSeek-V2: Ini adalah model pertama yang membuktikan bahwa arsitektur MLA mampu bekerja secara efektif pada skala besar. Peluncurannya membuka mata banyak peneliti bahwa kita bisa memangkas penggunaan memori secara drastis tanpa membuat model menjadi “bodoh”.
- DeepSeek-V3: Generasi penerusnya yang semakin menyempurnakan penggunaan MLA. Model ini berhasil mencapai performa setara dengan model tertutup terbaik dunia (seperti GPT-4 atau Claude 3.5 Sonnet) namun dengan biaya training dan inference yang jauh lebih rendah berkat efisiensi MLA.
2. Komunitas Open-Source & Riset Masa Depan
Karena DeepSeek merilis laporan teknis (technical paper) dan bobot modelnya (model weights) kepada publik, arsitektur MLA kini menjadi bahan studi utama bagi komunitas open-source.
- Banyak pengembang independen dan peneliti AI yang kini mulai bereksperimen mengadaptasi konsep kompresi Low-Rank ala MLA ini ke dalam arsitektur model lain.
- Diperkirakan dalam waktu dekat, kita akan melihat gelombang baru model AI hemat energi yang mengadopsi variasi dari teknologi ini, meninggalkan arsitektur lama yang boros sumber daya.
Singkatnya, jika hari ini MLA adalah “senjata rahasia” DeepSeek, besok ia berpotensi menjadi standar industri baru bagi semua pengembang yang ingin menciptakan AI yang cepat, murah, dan cerdas.
Multi-Head Latent Attention (MLA) bukan sekadar istilah teknis yang rumit, melainkan sebuah lompatan evolusi yang nyata dalam arsitektur kecerdasan buatan.
Selama bertahun-tahun, industri AI terjebak dalam dilema klasik memilih antara performa tinggi yang boros biaya (seperti MHA) atau efisiensi hemat biaya yang mengorbankan sedikit kualitas (seperti GQA).
MLA hadir memecahkan dilema tersebut. Dengan teknologi kompresi Low-Rank yang cerdas, MLA membuktikan bahwa kita bisa mendapatkan kualitas ingatan setara model terbaik dunia, namun dengan konsumsi memori yang sangat minim.
Kehadiran teknologi ini, khususnya melalui terobosan model DeepSeek, menandakan bahwa masa depan AI akan jauh lebih inklusif.
Kita bergerak menuju era di mana asisten cerdas yang mampu memproses ribuan halaman dokumen tidak lagi menjadi kemewahan yang mahal, melainkan alat yang cepat, murah, dan dapat diakses oleh siapa saja.
Jika Anda belum mencobanya, ini adalah saat yang tepat untuk menjajal model-model berbasis MLA dan merasakan sendiri bagaimana efisiensi ini bekerja nyata dalam mempercepat produktivitas Anda.
Baca Selanjutnya
GLM-4.6: Model AI Baru dengan Coding & Reasoning Lebih Kuat
Dua hari lalu, dunia AI kedatangan “pemain baru” yang langsung ramai dibicarakan: GLM-4.6. Model terbaru dari seri General Language Model (GLM) ini disebut-sebut membawa peningkatan signifikan dibanding versi sebelumnya, GLM-4.5. Bukan cuma sekadar update minor, GLM-4.6 hadir dengan kemampuan reasoning yang lebih kuat, jendela konteks lebih panjang, serta performa coding yang diklaim mampu menyaingi model-model […]
Decision Tree Classifier: Konsep, Cara Kerja & Contoh
Pernahkah kamu berpikir bagaimana sistem bisa membedakan email spam dari yang bukan? Atau bagaimana aplikasi kesehatan menebak penyakit dari gejala yang kamu isi? Salah satu algoritma machine learning yang sering dipakai untuk hal ini adalah decision tree classifier. Algoritma ini sederhana, mudah dipahami, tapi cukup kuat untuk menyelesaikan banyak masalah klasifikasi. Decision tree classifier bekerja […]