Decision Tree Classifier: Konsep, Cara Kerja & Contoh
Pernahkah kamu berpikir bagaimana sistem bisa membedakan email spam dari yang bukan? Atau bagaimana aplikasi kesehatan menebak penyakit dari gejala yang kamu isi?
Salah satu algoritma machine learning yang sering dipakai untuk hal ini adalah decision tree classifier.
Algoritma ini sederhana, mudah dipahami, tapi cukup kuat untuk menyelesaikan banyak masalah klasifikasi.
Decision tree classifier bekerja dengan prinsip percabangan keputusan, mirip seperti pohon yang punya akar (root), cabang (branch), dan daun (leaf).
Dengan pola ini, komputer bisa mengelompokkan data ke dalam kategori tertentu.
Baca Juga: Decision Tree Adalah: Pengertian, Jenis, Contoh, dan Cara Membuatnya
Apa Itu Decision Tree Classifier
Decision tree classifier adalah algoritma machine learning yang digunakan untuk mengklasifikasikan data ke dalam kategori tertentu.
Cara kerjanya mirip seperti pohon keputusan, di mana setiap pertanyaan bercabang membawa kita ke hasil akhir.
Strukturnya terdiri dari root node (akar sebagai titik awal), branch (cabang yang mewakili kondisi atau aturan), dan leaf node (daun yang mewakili hasil klasifikasi).
Setiap percabangan dibuat berdasarkan nilai feature tertentu dalam data.
Sederhananya, algoritma ini meniru cara manusia mengambil keputusan dengan pertanyaan ya/tidak. Misalnya: “Apakah buah ini berwarna merah?” → “Apakah ukurannya kecil?” → hasil akhirnya: apel atau ceri.
Karena sifatnya sederhana tapi efektif, decision tree classifier sering dipakai sebagai pintu masuk belajar machine learning. Selain itu, ia juga banyak digunakan dalam kasus nyata seperti deteksi spam atau prediksi penyakit.
Konsep Dasar & Teori Singkat
Salah satu inti dari decision tree classifier adalah bagaimana algoritma memilih feature terbaik untuk membagi data. Proses ini disebut splitting, yaitu memisahkan data ke dalam cabang-cabang berdasarkan nilai feature.
Untuk menentukan split terbaik, ada beberapa metrik yang biasa digunakan, seperti entropy dan gini index. Keduanya mengukur seberapa “murni” data dalam sebuah node—semakin homogen datanya, semakin baik split-nya.
Agar lebih mudah dipahami, perhatikan struktur pohon berikut:
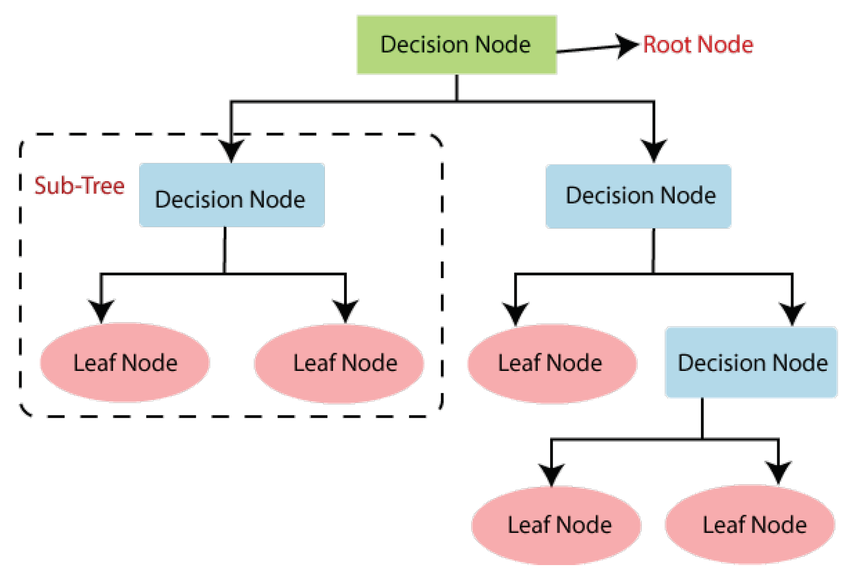
Sumber: researchgate
Pada gambar ini, root node adalah titik awal, decision node mewakili percabangan berdasarkan feature, dan leaf node menunjukkan hasil klasifikasi akhir. Kotak putus-putus adalah sub-tree, bagian kecil dari pohon yang bisa dianggap sebagai pohon mandiri.
Contoh Decision Classifier Dataset Mini
Bayangkan kita ingin mengklasifikasikan buah berdasarkan warnanya. Dataset sederhana bisa seperti ini:
| Warna | Ukuran | Buah |
| Merah | Kecil | Ceri |
| Merah | Besar | Apel |
| Hijau | Besar | Semangka |
| Hijau | Kecil | Jeruk |
Dari dataset tersebut, pohon bisa terbentuk seperti ini:
- Root Node: Warna
- Jika Merah → lanjut ke Ukuran
- Kecil → Ceri (Leaf Node)
- Besar → Apel (Leaf Node)
- Jika Hijau → lanjut ke Ukuran
- Kecil → Jeruk (Leaf Node)
- Besar → Semangka (Leaf Node)
- Jika Merah → lanjut ke Ukuran
Dengan pohon ini, kita bisa mengklasifikasikan buah baru hanya dengan melihat feature warna dan ukuran.
Kelebihan & Kekurangan Decision Tree Classifier
Salah satu alasan decision tree classifier populer adalah karena mudah dipahami. Algoritma ini tidak membutuhkan latar belakang teknis yang rumit untuk dimengerti, bahkan bisa divisualisasikan dengan diagram sederhana.
Kelebihan lainnya, decision tree tidak banyak membutuhkan data preprocessing.
Ia bisa menangani data kategori maupun numerik, sehingga fleksibel untuk berbagai kasus.
Namun, ada juga kekurangannya. Model ini rentan terhadap overfitting, terutama jika pohon terlalu dalam.
tree yang terlalu kompleks bisa bekerja baik pada data latih, tetapi buruk saat diuji pada data baru.
Selain itu, decision tree cukup sensitif terhadap perubahan kecil pada data. Perbedaan satu atau dua sampel saja bisa menghasilkan struktur pohon yang berbeda jauh.
Cara Kerja Decision Tree Classifier
Secara sederhana, decision tree classifier bekerja dengan memilih feature paling informatif, lalu membagi data berdasarkan nilai dari feature tersebut. Proses ini berulang sampai semua data bisa diklasifikasikan.
Langkah-langkah utamanya:
- Pilih feature terbaik
Algoritma menghitung nilai entropy atau gini index untuk tiap feature, lalu memilih yang paling informatif. - Lakukan splitting
Dataset dipecah menjadi beberapa cabang sesuai nilai feature. - Ulangi proses
Setiap cabang diperiksa kembali, lalu dipisah lagi menggunakan feature lain sampai mencapai kondisi berhenti. - Hasil klasifikasi
Cabang terakhir disebut leaf node, yang berisi label hasil klasifikasi, misalnya “spam” atau “not spam”.
Dengan cara ini, model belajar membuat keputusan secara bertahap, mirip seperti manusia yang menyaring pilihan lewat serangkaian pertanyaan.
Implementasi Praktis Decision Tree Classifier
Salah satu cara paling mudah mencoba decision tree classifier adalah dengan menggunakan library scikit-learn di Python.
Library ini sudah menyediakan class DecisionTreeClassifier untuk membangun model pohon keputusan.
Berikut contoh kode sederhana dengan dataset Iris yang terkenal di dunia machine learning:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# Load dataset Iris
iris = load_iris()
X, y = iris.data, iris.target
# Buat model Decision Tree
model = DecisionTreeClassifier(criterion="gini", max_depth=3, random_state=42)
model.fit(X, y)
# Visualisasi Decision Tree
plt.figure(figsize=(12,8))
plot_tree(model,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True)
plt.show()Kode di atas akan menghasilkan diagram pohon berwarna yang memperlihatkan percabangan keputusan. Setiap node menampilkan feature yang digunakan untuk split, nilai ambang batas, serta distribusi kelas.
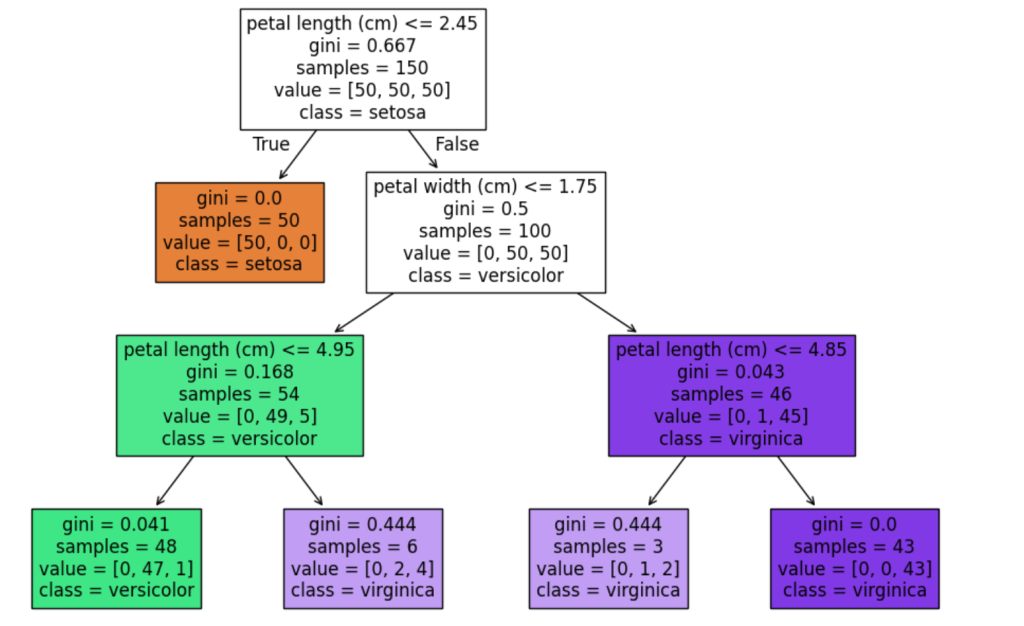
Dengan visualisasi ini, pembaca bisa langsung melihat bagaimana model bekerja dalam mengklasifikasikan data.
Dari hasil ini, terlihat bagaimana decision tree membuat aturan sederhana untuk mengklasifikasikan jenis bunga berdasarkan panjang dan lebar petalnya.
Itu dia informasi seputar decision tree classifier, mulai dari konsep dasar, cara kerja, hingga contoh implementasi dengan Python.
Algoritma ini sederhana, mudah divisualisasikan, dan jadi salah satu fondasi penting di dunia machine learning.
Meskipun punya keterbatasan seperti risiko overfitting, decision tree tetap jadi pilihan populer untuk belajar algoritma klasifikasi.
Bahkan, banyak model canggih seperti random forest dan gradient boosting lahir dari pengembangan metode ini.
Semoga penjelasan ini bisa jadi pintu masuk buat kamu yang ingin lebih dalam mengeksplorasi machine learning.
Kalau sudah paham decision tree classifier, langkah selanjutnya tinggal memperluas ke algoritma lain yang lebih kompleks.
Baca Selanjutnya
Apa Itu Multi-Head Latent Attention (MLA)? Rahasia Efisiensi DeepSeek
Dunia Artificial Intelligence (AI) belakangan ini sedang ramai membicarakan sebuah pergeseran besar. Jika sebelumnya kompetisi antar pengembang AI hanya berfokus pada siapa yang paling “pintar”, kini fokus tersebut meluas ke arah efisiensi. Kemunculan model-model terbaru, seperti DeepSeek, yang mampu menyamai performa model closed-source raksasa namun dengan biaya operasional yang jauh lebih rendah, memicu tanda tanya […]
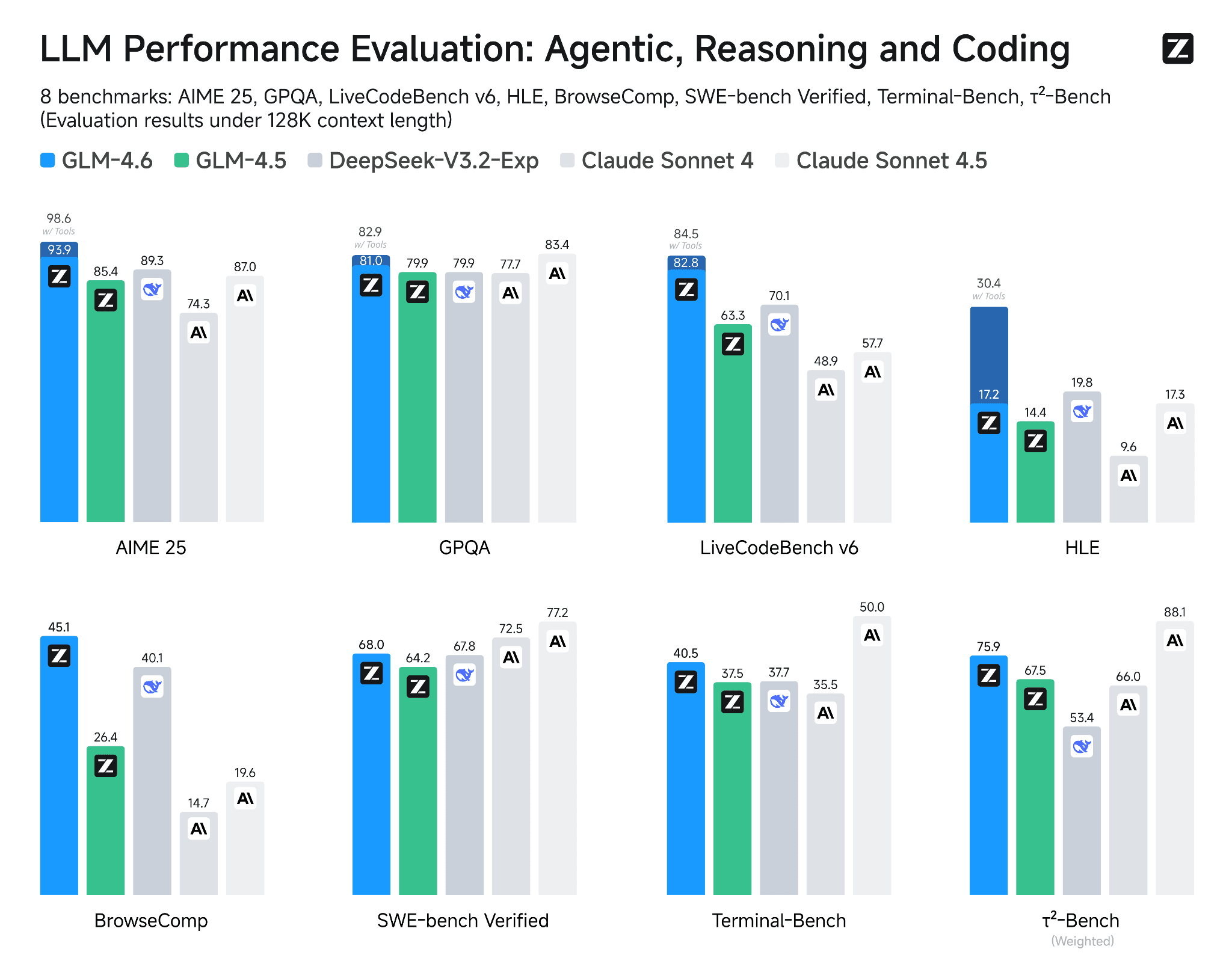
GLM-4.6: Model AI Baru dengan Coding & Reasoning Lebih Kuat
Dua hari lalu, dunia AI kedatangan “pemain baru” yang langsung ramai dibicarakan: GLM-4.6. Model terbaru dari seri General Language Model (GLM) ini disebut-sebut membawa peningkatan signifikan dibanding versi sebelumnya, GLM-4.5. Bukan cuma sekadar update minor, GLM-4.6 hadir dengan kemampuan reasoning yang lebih kuat, jendela konteks lebih panjang, serta performa coding yang diklaim mampu menyaingi model-model […]