Apa itu Transformers Model? Arsitektur, Cara Kerja & Evolusi AI
Bayangkan Anda sedang mengetik pesan di ponsel. Setiap kali mengetik satu kata, ponsel akan memberikan tiga saran kata berikutnya. Jika Anda terus-menerus mengeklik saran tersebut, kalimat yang dihasilkan pasti akan kacau dan kehilangan makna. Mengapa? Karena teknologi di ponsel Anda tidak memahami konteks keseluruhan pesan—ia hanya menebak kata apa yang biasanya muncul setelah kata terakhir.
Di sinilah Transformers model membawa revolusi besar.
Sejak Google merilis paper ilmiah legendaris “Attention Is All You Need“ pada tahun 2017, arsitektur deep learning ini mengubah total cara mesin memahami bahasa manusia.
Tidak seperti teknologi lama yang membaca kata demi kata secara berurutan, Transformer mampu memproses seluruh informasi secara bersamaan (parallel processing) dan menjaga konteks obrolan tetap utuh dari awal hingga akhir.
Kemampuan menjaga konteks inilah yang membuat kecerdasan buatan seperti OpenAI GPT-5, Claude, hingga Google Gemini mampu menulis esai, menjawab pertanyaan kompleks, bahkan lulus ujian manusia dengan sangat koheren.
Bagi para praktisi AI dan data scientist, memahami Transformer bukan lagi pilihan, melainkan kunci utama untuk menguasai era Generative AI dan Computer Vision saat ini.
Artikel ini akan membedah rahasia di balik arsitektur Transformer, mulai dari mekanisme self-attention hingga inovasi efisiensi terbarunya secara sederhana dan terstruktur.
Baca Juga: Decision Tree: Pengertian, Manfaat, & Cara Kerja
Apa itu Transformer Model Architecture?
Transformer model adalah arsitektur jaringan saraf tiruan (deep learning) yang dirancang khusus untuk memproses data sekuensial atau berurutan, seperti rangkaian kata dalam kalimat. Model ini merevolusi dunia kecerdasan buatan karena kemampuannya dalam memahami konteks dan makna terdalam dari suatu data secara utuh.
Jika Anda pernah menggunakan aplikasi AI generatif populer saat ini seperti ChatGPT, Claude, atau Gemini, semua teknologi tersebut dibangun di atas fondasi Transformer. Bahkan, singkatan GPT sendiri adalah Generative Pre-trained Transformer.
Arsitektur ini pertama kali diperkenalkan oleh tim peneliti Google dalam paper ilmiah legendaris berjudul “Attention Is All You Need” pada tahun 2017. Awalnya, Transformer diciptakan untuk menyempurnakan tugas penerjemahan bahasa otomatis guna menggantikan teknologi lama seperti Recurrent Neural Network (RNN).
Namun dalam perkembangannya, model ini justru memicu pergeseran paradigma besar dalam sejarah kecerdasan buatan. Oleh karena itu, para peneliti di Stanford University bahkan menyebut Transformer sebagai foundation models atau model fondasi karena skalanya yang masif dan kemampuannya mengubah peta industri AI.
Mengapa Transformer Sangat Spesial?
Ada beberapa mekanisme internal yang membuat model Transformer jauh lebih unggul daripada arsitektur AI pendahulunya:
- Mekanisme Self-Attention: Teknik matematika ini memungkinkan model untuk melacak dan mendeteksi hubungan antara elemen data yang saling berjauhan. Melalui fitur ini, AI bisa mengetahui bagaimana setiap kata dalam satu kalimat saling memengaruhi dan bergantung satu sama lain.
- Pemrosesan Paralel (Parallel Processing): Berbeda dengan model lama yang harus membaca data satu per satu secara berurutan, Transformer mampu menganalisis seluruh rangkaian data secara bersamaan. Hal ini membuat waktu pelatihan (training) model menjadi jauh lebih cepat dan efisien.
- Skalabilitas dan Fleksibilitas: Model ini sangat tangguh ketika dilatih menggunakan dataset yang berukuran sangat raksasa dan bisa diterapkan untuk berbagai tugas yang berbeda.
Meskipun paling sering dibahas dalam ranah pemrosesan bahasa alami atau Natural Language Processing (NLP) seperti untuk pembuatan chatbot, penerjemahan, dan perangkuman teks, kemampuan hebat Transformer tidak terbatas pada kata-kata saja.
Karena arsitektur ini sangat ahli dalam membaca pola hubungan antar data, Transformer kini juga meraih performa elit di berbagai bidang AI lainnya.
Teknologi ini digunakan dalam Computer Vision melalui Vision Transformers (ViT) untuk mendeteksi objek dalam gambar, digunakan untuk pengenalan suara (speech recognition), memprediksi penipuan finansial, melakukan prakiraan data berbasis waktu (time series forecasting), hingga membantu riset biomedis.
Sejarah dan Evolusi Transformer Model
Perjalanan arsitektur Transformer mencerminkan salah satu akselerasi teknologi tercepat dalam sejarah umat manusia. Hanya dalam hitungan tahun, teknologi ini berevolusi dari sekadar eksperimen laboratorium menjadi penggerak infrastruktur digital dunia.
Berikut adalah linimasa penting bagaimana Transformer mengubah lanskap kecerdasan buatan:
2017: Titik Awal “Attention Is All You Need”
Sebelum tahun 2017, dunia deep learning sangat bergantung pada arsitektur seperti RNN dan LSTM untuk memproses bahasa. Namun, model-model tersebut lambat karena harus memproses data secara berurutan.
Titik balik terjadi ketika tim peneliti Google merilis paper ilmiah legendaris berjudul “Attention Is All You Need”. Mereka memperkenalkan arsitektur Transformer yang membuang metode lama dan menggantinya dengan mekanisme self-attention.
Konsep ini langsung diaplikasikan secara praktis melalui paket Tensor2Tensor milik TensorFlow, yang kemudian diikuti oleh komunitas akademis seperti Harvard NLP group dengan menyediakan panduan beranotasi berbasis PyTorch.
2018 ke 2021: Lahirnya Model Fondasi dan Era GPT-3
Memasuki tahun 2018, industri AI mulai menyebut momen ini sebagai watershed moment (titik pergantian zaman) bagi NLP. Google meluncurkan BERT pada tahun 2018 yang merevolusi cara mesin pencari memahami maksud pertanyaan manusia.
Lompatan besar berikutnya terjadi pada tahun 2020 ketika OpenAI mengumumkan GPT-3. Dalam hitungan minggu, model ini memukau dunia karena kemampuannya menulis puisi, menyusun kode program, menggubah lagu, hingga merancang situs web.
Melihat fenomena ini, para peneliti dari Stanford University pada tahun 2021 menerbitkan sebuah dokumen penting yang resmi melabeli inovasi ini sebagai “foundation models“ (model fondasi), menegaskan peran krusialnya dalam mengubah peta masa depan AI.
2023 ke 2024: Ledakan Otomatisasi, Multimodal, dan Gerakan Open-Source
Tahun 2023 menandai awal persaingan sengit antara model berbayar (proprietary) dan model terbuka (open-source). OpenAI merilis GPT-4 yang memperkenalkan kemampuan multimodal awal, yang kemudian disempurnakan lewat GPT-4o pada tahun 2024 dengan menyatukan pemrosesan teks, penglihatan (vision), dan audio dalam satu model tunggal.
Di sisi lain, platform seperti Hugging Face menjadi pusat demokratisasi teknologi ini. Momentum open-source meledak setelah Meta merilis rumpun model Llama pada tahun 2023.
Gerakan open-weights ini membuktikan bahwa para pengembang independen tidak lagi harus bergantung pada ekosistem perusahaan tertutup untuk membangun AI tingkat tinggi.
Sepanjang tahun 2024 hingga awal 2025, pengembangan model terbuka melaju sangat kencang. Meta meluncurkan Llama 3.1 yang berukuran masif, disusul oleh efisiensi arsitektur dari startup seperti Mistral, serta kemunculan model penalaran kuat dari DeepSeek. Model-model ini membuktikan bahwa teknologi terbuka mampu menandingi, bahkan terkadang melampaui performa raksasa berbayar.
Akhir 2024 ke 2026: Era Penalaran Kompleks dan Agen AI Otonom
Pada akhir tahun 2024, industri AI kembali bergeser dari model yang sekadar “menebak kata” menjadi model yang “berpikir”. OpenAI meluncurkan seri o1, bersamaan dengan DeepSeek yang merilis model open-source R1.
Keduanya memperkenalkan metode internal chain-of-thought (rantai pemikiran), di mana AI akan melakukan penalaran logika dan matematika yang rumit di balik layar sebelum memberikan jawaban akhir kepada pengguna.
Kini, memasuki tahun 2026, lanskap AI telah bergeser sepenuhnya. AI tidak lagi sekadar menjadi asisten teks yang interaktif. Lewat peluncuran keluarga model GPT-5 serta generasi penerus seperti rumpun Llama 4, Transformer telah bertransformasi menjadi sistem otonom (autonomous agents).
AI modern saat ini sudah terintegrasi ke dalam infrastruktur perusahaan dengan kemampuan perencanaan multi-langkah (multi-step planning), memori jangka panjang yang kuat, serta kemampuan mengeksekusi alur kerja kompleks secara mandiri.
Mengapa Transformer Model Sangat Penting?
Pentingnya arsitektur Transformer dalam dunia kecerdasan buatan tidak lepas dari kemampuannya mendobrak batasan-batasan teknologi yang ada sebelumnya. Ada tiga alasan utama mengapa Transformer menjadi begitu krusial dan penting saat ini:
1. Fleksibilitas Tinggi (Versatility)
Transformer tidak hanya diciptakan untuk satu tugas spesifik. Kemampuannya dalam mengenali pola membuat model ini bisa diterapkan di berbagai bidang yang sangat luas. AI berbasis Transformer mampu menulis esai rumit dalam hitungan detik, memahami perintah suara, mengenali objek dalam gambar, memprediksi penipuan finansial, hingga memetakan pola genetik yang ditemukan dalam DNA manusia.
2. Keunggulan Telak atas Arsitektur RNN dan CNN
Sebelum Transformer lahir, dunia AI didominasi oleh arsitektur Recurrent Neural Networks (RNN), termasuk variannya seperti LSTM (Long Short Term Memory), dan Convolutional Neural Networks (CNN). Transformer mengungguli keduanya lewat cara yang revolusioner:
- Menggantikan Proses Sekuensial RNN: RNN memproses data secara berurutan atau satu demi satu. Akibatnya, RNN sangat lambat dan mengalami kesulitan besar untuk mengingat hubungan kata yang jaraknya berjauhan (long-range dependencies). Artinya, RNN hanya efektif untuk teks pendek. Sebaliknya, Transformer mampu melihat dan menganalisis seluruh urutan data secara bersamaan.
- Melampaui Sifat Lokal CNN: Dalam memproses data visual (gambar), CNN bekerja secara lokal menggunakan konvolusi untuk memeriksa piksel dalam kelompok-kelompok kecil secara bertahap. Hal ini membuat CNN kesulitan melihat korelasi antar piksel yang letaknya berjauhan. Mekanisme perhatian pada Transformer tidak memiliki batasan tersebut, sehingga ia bisa langsung memahami seluruh bagian gambar secara utuh.
3. Efisiensi Pelatihan lewat Pemrosesan Paralel
Karena tidak perlu memproses data satu per satu, seluruh langkah komputasi pada Transformer dapat berjalan secara bersamaan (parallelization).
Karakteristik ini membuat Transformer mampu memanfaatkan seluruh kekuatan, kecepatan, dan daya komputasi yang ditawarkan oleh kartu grafis modern (GPU) secara maksimal, baik saat proses pelatihan (training) maupun saat digunakan (inference).
Dampaknya, waktu pelatihan menjadi jauh lebih singkat. Efisiensi ini pula yang membuka peluang bagi para peneliti untuk melatih Transformer menggunakan dataset raksasa yang belum pernah ada sebelumnya melalui metode self-supervised learning.
4. Menghilangkan Kebutuhan Data Berlabel (Positional Encoding)
Pada model AI tradisional, proses persiapan data membutuhkan waktu yang sangat lama karena manusia harus memberi label satu per satu pada materi pelatihan.
Transformer menyelesaikan masalah ini dengan menggunakan positional encoding untuk menentukan pola dan urutan antar elemen data secara otomatis.
Fitur ini memangkas kebutuhan akan data berlabel yang mahal dan menyita waktu, sehingga model bisa langsung belajar dari data mentah dalam jumlah masif.
Mengapa Model Lama Ditinggalkan?
Sebelum arsitektur Transformer mendominasi industri kecerdasan buatan, bidang pemrosesan bahasa alami (NLP) sangat bergantung pada model lawas seperti Recurrent Neural Networks (RNN) dan Long Short-Term Memory (LSTM).
Meskipun sempat menjadi standar industri, model-model ini akhirnya ditinggalkan karena memiliki batasan struktural yang mendasar saat dihadapkan pada kebutuhan AI modern.
Kelemahan RNN dan LSTM: Lambat dan Sering “Lupa”
Masalah utama dari RNN dan LSTM terletak pada metode pemrosesan datanya yang bersifat sekuensial atau berurutan.
- Proses yang Lambat: Model-model lama ini membaca teks kata demi kata, persis seperti manusia. AI harus menyelesaikan pemrosesan kata pertama terlebih dahulu sebelum bisa berpindah ke kata kedua, dan begitu seterusnya. Sifat penanganan data yang mengantre ini membuat komputasi menjadi sangat lambat dan tidak bisa memanfaatkan kekuatan penuh dari perangkat keras modern seperti GPU secara maksimal.
- Masalah Hilangnya Konteks (Vanishing Gradient): Karena membaca secara berurutan, RNN dan LSTM memiliki memori jangka pendek yang payah. Ketika dihadapkan pada paragraf atau dokumen yang panjang, AI sering kali “lupa” dengan konteks kata-kata yang berada di awal kalimat. Akibatnya, hubungan emosional, subjek, atau makna tersembunyi yang letaknya berjauhan gagal ditangkap dengan akurat.
Solusi dari Transformer: Pemrosesan Paralel yang Instan
Transformer hadir dengan membawa paradigma baru yang menyelesaikan seluruh hambatan di atas secara elegan melalui dua solusi utama:
- Pemrosesan Paralel (Parallel Processing): Transformer membuang metode antrean kata demi kata. Arsitektur ini mampu melihat, membaca, dan memproses seluruh kata dalam satu kalimat bahkan satu dokumen besar secara bersamaan dalam satu waktu. Hal ini memangkas waktu pelatihan model secara drastis dari yang dulunya memakan waktu berminggu-minggu menjadi jauh lebih singkat.
- Mempertahankan Konteks Tanpa Batas: Dengan memproses semua data secara simultan dan memanfaatkan mekanisme perhatian, tidak ada lagi istilah “lupa konteks”. Transformer mampu melihat hubungan keterkaitan antara kata pertama dan kata terakhir dalam sebuah buku dengan tingkat akurasi yang sama kuatnya, membuat teks atau respons yang dihasilkan AI menjadi sangat masuk akal dan koheren.
Cara Kerja dan Arsitektur Transformers Model
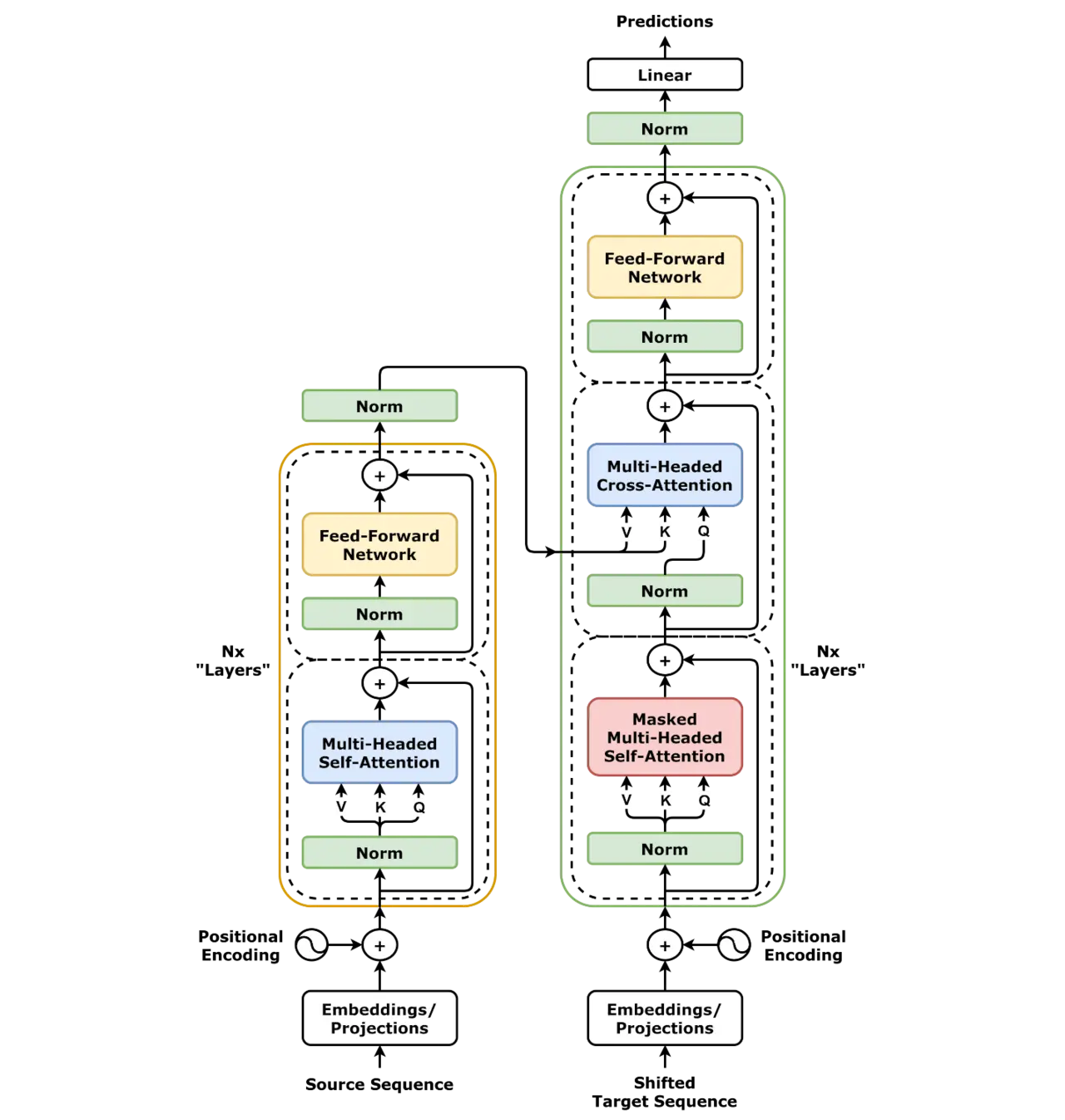
Meskipun terlihat rumit pada pandangan pertama, arsitektur Transformer sebenarnya adalah gabungan dari beberapa komponen modular yang memiliki fungsi spesifik. Secara garis besar, arsitektur aslinya berbasis desain Encoder-Decoder, yang bertugas mengubah urutan input (seperti kalimat bahasa Inggris) menjadi urutan output (seperti terjemahan bahasa Spanyol).
Mari kita bedah alur kerja dan komponen utama di dalam Transformer model dari awal hingga menghasilkan output:
1. Tahap Persiapan: Tokenization & Embedding
Sebelum masuk ke dalam jaringan saraf, teks teks manusia harus diubah ke dalam bentuk yang dipahami komputer.
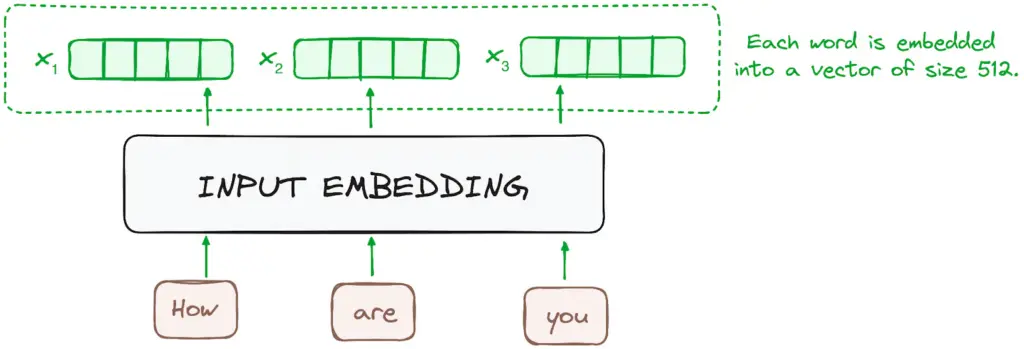
- Tokenization: Kalimat dipotong-potong menjadi unit terkecil yang disebut token (bisa berupa kata, imbuhan, atau tanda baca). Setiap token unik ini diberi nomor ID khusus.
- Input Embedding: Nomor ID token kemudian diubah menjadi vector (rangkaian angka panjang). Embedding ini memastikan kata-kata yang memiliki makna mirip akan berada di posisi ruang vektor yang berdekatan (misalnya kata “kucing” dan “anak kucing”).
2. Positional Encoding: Memberi Tahu Urutan Kata
Karena Transformer memproses semua kata secara bersamaan (parallel processing), model ini tidak tahu mana kata yang di depan atau di belakang. Untuk mengatasinya, Transformer menggunakan Positional Encoding.
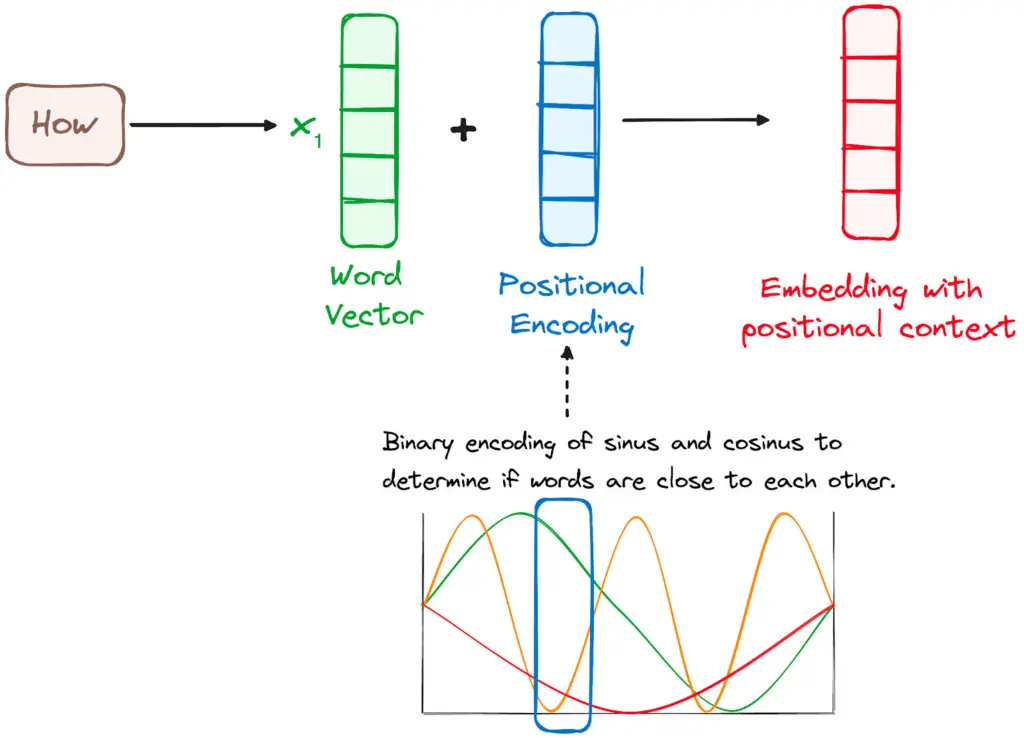
Teknik ini menambahkan vektor matematika (menggunakan fungsi sinus dan kosinus) ke dalam vektor embedding. Hasilnya, kalimat “Saya tidak sedih, saya bahagia” dan “Saya tidak bahagia, saya sedih” akan memiliki representasi vektor yang berbeda total karena AI sekarang tahu posisi persis tiap kata dalam kalimat.
3. Jantung Utama: Transformer Block
Setelah data siap, data tersebut masuk ke dalam tumpukan Transformer Block. Di dalam blok inilah proses magis terjadi melalui dua komponen utama:
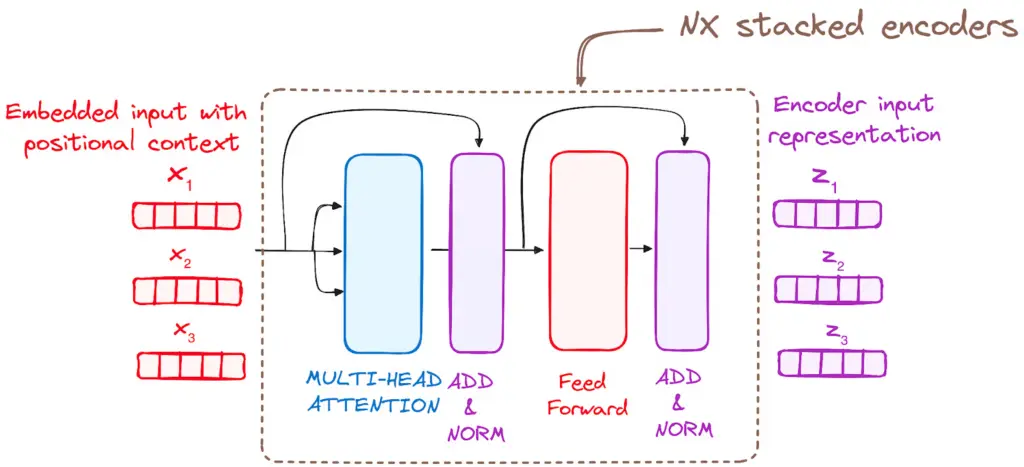
A. Multi-Head Self-Attention Mechanism
Ini adalah fitur paling krusial. Self-attention memungkinkan AI melihat seluruh kalimat dan menghitung seberapa besar hubungan atau pengaruh satu kata terhadap kata lainnya.
Di dalam sistem ini, setiap token menghasilkan tiga vektor internal layaknya basis data relasional:
- Query (Q): Informasi apa yang sedang dicari oleh token tersebut.
- Key (K): Informasi apa yang dimiliki oleh token lain.
- Value (V): Isi informasi yang akan diambil jika Query dan Key cocok.
Melalui perkalian matriks, sistem menghitung bobot perhatian (attention weights). Kata yang sangat relevan secara konteks akan mendapat bobot mendekati satu, sementara yang tidak relevan mendekati nol.
Disebut Multi-Head Attention karena proses pencarian hubungan ini dilakukan beberapa kali secara paralel di “kepala” (heads) yang berbeda-beda, sehingga AI bisa menangkap makna dari berbagai sudut pandang sekaligus.
B. Feed-Forward Neural Network (FFN)
Setelah konteks antar kata dikumpulkan oleh lapisan attention, data tersebut dikirim ke jaringan saraf feed-forward standar untuk diproses lebih dalam dan disempurnakan fiturnya secara independen pada setiap posisi kata.
C. Residual Connections dan Layer Normalization
Di setiap akhir sub-lapisan, terdapat residual connection (jalur pintas yang menambahkan input asli langsung ke output lapisan) diikuti dengan proses normalization.
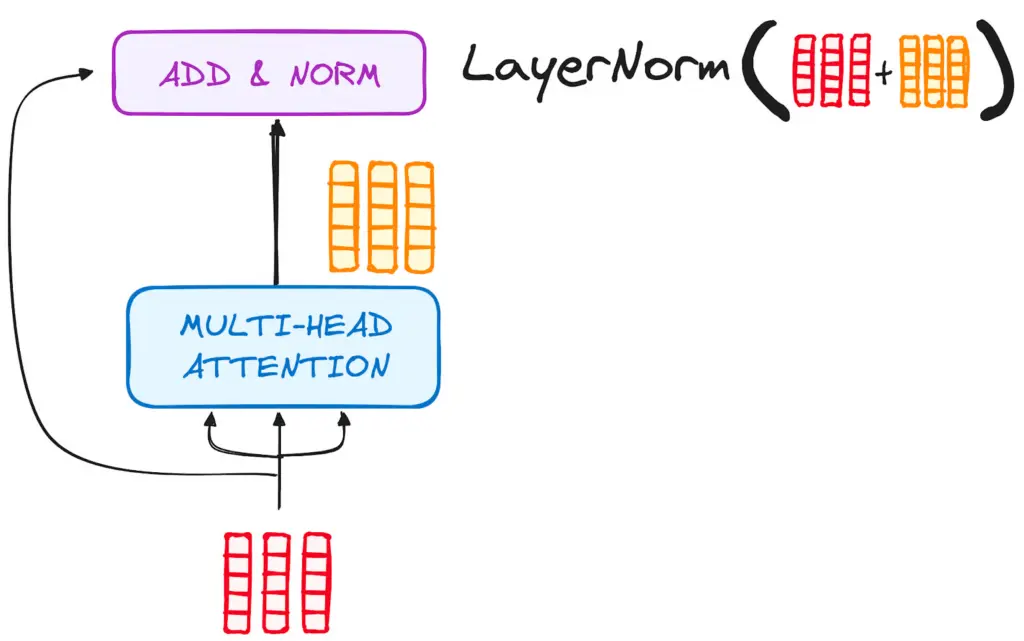
Fitur ini sangat penting untuk menjaga stabilitas pelatihan, mencegah hilangnya informasi penting dari teks asli, dan menghindari masalah vanishing gradient pada model yang sangat dalam.
4. Pembagian Tugas: Arsitektur Encoder vs. Decoder
Dalam struktur globalnya, proses ini dibagi menjadi dua menara:
- Workflow Encoder: Bertugas membaca teks input (misal: “How are you?”) dan mengubahnya menjadi representasi matriks abstrak yang kaya akan pemahaman konteks.
- Workflow Decoder: Bertugas menghasilkan teks output secara bertahap (autoregressive).
Decoder memulai dengan token awal (start token), lalu membaca hasil analisis dari Encoder dikombinasikan dengan kata-kata yang sudah ia hasilkan sebelumnya.
- Masked Self-Attention: Di dalam Decoder, lapisan attention diberi “masker” agar AI tidak bisa mengintip kata-kata di masa depan saat latihan. AI hanya boleh melihat kata-kata yang sudah tertulis sebelumnya.
- Cross-Attention: Di lapisan ini, Decoder mengirimkan Query, sementara Key dan Value diambil langsung dari output Encoder. Proses ini membuat Decoder tahu bagian kata mana dari input asli yang harus paling diperhatikan saat menghasilkan kata berikutnya.
5. Tahap Akhir: Linear Classifier & Softmax Layer
Setelah melewati berbagai blok, output final dari Decoder berupa angka-angka abstrak akan dilempar ke sebuah lapisan Linear Classifier. Lapisan ini memetakan angka tersebut ke seluruh kosakata (vocabulary) yang dimiliki AI (misal berisi 50.000 kata).
Terakhir, fungsi Softmax mengubah skor-skor kata tersebut menjadi distribusi probabilitas (total nilai menjadi 1 atau 100%).
Kata dengan probabilitas tertinggi akan dipilih sebagai kata berikutnya. Proses ini diulang terus-menerus (kata demi kata) sampai model mengeluarkan token khusus yang menandakan kalimat telah selesai (end token).
Kelebihan Utama Transformers Model
Dibandingkan dengan arsitektur jaringan saraf tradisional, Transformer model membawa sejumlah keunggulan revolusioner yang membuatnya diadopsi secara masif di berbagai industri teknologi.
Berikut adalah kelebihan utama yang membuat Transformer begitu unggul:
1. Kecepatan Training yang Luar Biasa (Berkat Parallel Processing)
Kelebihan paling signifikan dari Transformer adalah kemampuannya membuang metode pemrosesan sekuensial (antrean kata demi kata). Karena semua kata atau elemen dalam data diproses secara bersamaan, waktu pelatihan (training time) model menjadi jauh lebih singkat. Arsitektur ini sangat cocok dengan perangkat keras modern seperti GPU atau TPU, sehingga memungkinkan para peneliti melatih model raksasa dalam waktu yang realistis.
2. Skalabilitas yang Sangat Tinggi (Scalability)
Transformer dirancang untuk menjadi semakin cerdas ketika diberikan data dan parameter yang lebih besar. Model ini mampu menampung miliaran hingga triliunan parameter tanpa mengalami penurunan performa (stagnan). Skalabilitas inilah yang memungkinkan lahirnya model-model fondasi berukuran masif (Large Language Models) seperti GPT-4o, Llama 3, hingga GPT-5.
3. Kemampuan Menangkap Konteks Jarak Jauh (Long-Range Dependencies)
Pada model lama seperti RNN atau LSTM, AI akan mulai “lupa” arti kata di awal kalimat jika teksnya terlalu panjang. Transformer mengatasi masalah ini lewat mekanisme self-attention. AI dapat mendeteksi hubungan, keterkaitan, dan nuansa makna antar kata meskipun letaknya terpisah ratusan halaman dalam satu dokumen. Hal ini menghasilkan output teks yang sangat koheren, logis, dan masuk akal.
4. Fleksibilitas Multimodal (Versatility)
Transformer tidak hanya terbatas untuk mengolah teks (bahasa). Karena arsitekturnya bekerja berdasarkan pengenalan pola hubungan antar data, model ini bisa diadaptasi untuk jenis data apa pun. Transformer terbukti meraih performa elit dalam bidang Computer Vision (melalui Vision Transformers untuk memproses gambar), pengenalan suara (speech recognition), pengkodean pemrograman, hingga analisis struktur biologi dan DNA.
5. Efisiensi Data Lewat Self-Supervised Learning
Berkat fitur positional encoding dan mekanisme internalnya, Transformer tidak selalu membutuhkan data yang telah diberi label secara manual oleh manusia (proses yang mahal dan memakan waktu). Model ini bisa melakukan training langsung menggunakan data mentah yang ada di internet (seperti artikel web, buku, dan kode sumber) untuk mempelajari struktur bahasa secara mandiri sebelum disempurnakan.
Transformer Model dalam NLP (Natural Language Processing)
Meskipun saat ini penerapannya sudah meluas ke berbagai bidang, Transformer model paling sering diasosiasikan dengan Natural Language Processing (NLP) karena arsitektur ini awalnya memang diciptakan untuk menyempurnakan penerjemahan bahasa otomatis. Kehadiran Transformer menjadi pemicu lahirnya Large Language Models (LLMs) yang mengawali era Generative AI saat ini.
Dalam dunia NLP, perkembangan model berbasis Transformer terpecah menjadi dua cabang evolusi utama sesuai dengan fokus fungsinya:
1. Autoregressive Decoder-Only LLM (Fokus pada Pembuatan Teks)
Sebagian besar LLM yang populer dan dikenal luas oleh publik saat ini masuk ke dalam kategori autoregressive decoder-only. Contohnya meliputi model berbayar (closed-source) seperti seri GPT dari OpenAI dan Claude dari Anthropic, hingga model terbuka (open-source) seperti Meta Llama dan IBM Granite.
- Cara Kerja: Model ini dilatih menggunakan metode self-supervised learning. AI akan diberikan kata pertama dari sebuah teks, lalu ditugaskan untuk menebak kata berikutnya secara berulang (iterative) sampai kalimat selesai.
- Fungsi Utama: Model jenis ini dirancang khusus untuk pembuatan teks (text generation). Berkat mekanisme self-attention yang kuat, model ini mampu mengekstrak konteks dari input pengguna dan menjaga aliran teks tetap koheren dan berkesinambungan. Selain menulis teks baru, kemampuan ini membuatnya sangat ahli dalam merangkum dokumen (summarization) serta menjawab pertanyaan (question answering).
2. Encoder-Decoder Masked Language Model / MLM (Fokus pada Pemahaman Konteks)
Cabang evolusi besar lainnya adalah model berbasis Masked Language Model (MLM), dengan BERT (dari Google) beserta turunan-turunannya sebagai pelopor utama.
- Cara Kerja: Berbeda dengan tipe pertama, dalam proses pelatihannya, model MLM diberikan sebuah sampel teks di mana beberapa kata di dalamnya sengaja disembunyikan atau “dimasker” (di-mask). Tugas AI adalah menebak dan melengkapi kata yang hilang tersebut dengan melihat kata-kata di kiri dan kanannya secara dua arah (bidirectional).
- Fungsi Utama: Metode pelatihan ini memang kurang efektif jika digunakan untuk membuat teks panjang secara mandiri (text generation). Namun, pendekatan ini membuat model MLM jauh lebih unggul dalam tugas-tugas yang membutuhkan pemahaman konteks mendalam dan pemetaan makna, seperti penerjemahan bahasa otomatis, pengelompokan teks (text classification), serta pembuatan representasi kata ke dalam angka (learning embeddings) untuk mesin pencari.
Transformer Model di Bidang Lain (Luar NLP)
Meskipun awalnya dirancang khusus untuk mengolah bahasa manusia, Transformer model pada dasarnya dapat digunakan dalam situasi apa pun yang melibatkan data sekuensial (data yang berurutan). Kemampuan ini memicu lahirnya berbagai model berbasis Transformer di luar bidang teks, mulai dari sistem multimodal hingga analisis gambar.
Berikut adalah bagaimana Transformer merevolusi bidang-bidang selain NLP:
1. Computer Vision (Vision Transformers / ViT)
Gambar secara alami bukanlah data yang berurutan seperti kalimat. Untuk menyiasatinya, para peneliti menggunakan trik konseptual yang disebut patch embeddings.
Gambar akan dipotong-potong menjadi kotak-kotak kecil (seperti potongan puzzle). Setiap potongan kotak ini kemudian dianggap sebagai satu “kata” atau token, lalu diurutkan menjadi sebuah rangkaian sekuensial sebelum dimasukkan ke dalam mekanisme attention.
Berkat metode ini, Vision Transformers (ViTs) berhasil meraih performa elit yang menandingi atau bahkan melampaui arsitektur CNN tradisional dalam berbagai tugas berat seperti:
- Object Detection: Mendeteksi dan mengenali objek di dalam foto.
- Image Segmentation: Memisahkan objek dari latar belakangnya secara presisi.
- Image Captioning & Visual Question Answering: Menjelaskan isi foto dalam bentuk teks atau menjawab pertanyaan berdasarkan gambar yang diberikan.
2. Sistem Multimodal
Transformer menjadi jembatan yang menyatukan berbagai jenis data berbeda ke dalam satu sistem AI tunggal.
Dengan melakukan penyelarasan (fine-tuning) pada LLM dasar, ilmuwan bisa menciptakan AI multimodal (seperti GPT-4o atau Gemini) yang tidak hanya paham teks, tetapi juga bisa langsung membaca gambar, mendengar audio, dan melihat video secara bersamaan tanpa perlu memisah-misah modelnya.
3. Data yang Inheren Sekuensial (Audio, Video, dan Time Series)
Ada beberapa jenis data yang secara alami sudah berurutan, sehingga sangat cocok dengan cara kerja Transformer:
- Audio dan Video: Karena video adalah urutan dari rangkaian gambar per bingkai (frame) dan audio adalah urutan gelombang suara berbasis waktu, Transformer bisa dengan mudah memahami alur cerita video atau melakukan pengenalan suara (speech recognition).
- Time Series Forecasting: Dalam dunia finansial dan bisnis, Transformer digunakan untuk memprediksi masa depan (seperti pergerakan harga saham, tren cuaca, atau angka penjualan) dengan cara menganalisis pola urutan data historis di masa lalu.
FAQ (Pertanyaan yang Sering Diajukan)
1. Apa perbedaan utama antara Transformer model dengan model AI lama seperti RNN?
Perbedaan utamanya terletak pada cara memproses data. Model lama seperti RNN membaca teks secara berurutan kata demi kata (sekuensial), sehingga proses komputasinya lambat dan sering kehilangan konteks pada kalimat panjang. Sementara itu, Transformer menggunakan pemrosesan paralel (parallel processing) yang memungkinkan AI membaca seluruh kalimat secara bersamaan, sehingga jauh lebih cepat dan sangat akurat dalam menjaga konteks.
2. Apakah ChatGPT menggunakan arsitektur Transformer model?
Ya, betul. Seluruh ekosistem ChatGPT dibangun di atas arsitektur Transformer. Bahkan, huruf “T” di dalam singkatan GPT sendiri merupakan kepanjangan dari Transformer (Generative Pre-trained Transformer). ChatGPT memanfaatkan varian autoregressive decoder-only untuk menghasilkan teks baru kata demi kata secara logis.
3. Mengapa Transformer model juga digunakan untuk mengolah gambar (Computer Vision)?
Meskipun awalnya dibuat untuk teks, Transformer bekerja berdasarkan prinsip pengenalan pola hubungan antar data sekuensial. Dalam dunia Computer Vision, gambar akan dipotong menjadi kotak-kotak kecil (patch embeddings) yang diurutkan seperti rangkaian kata. Metode ini membuat Vision Transformers (ViTs) mampu memahami hubungan antar bagian gambar secara utuh dan melampaui performa model tradisional seperti CNN.
4. Apa saja contoh model AI populer yang menggunakan arsitektur Transformer?
Saat ini, hampir semua AI terkemuka di dunia menggunakan Transformer sebagai fondasinya. Contohnya meliputi model komersial (closed-source) seperti seri GPT-4o/GPT-5 dari OpenAI, Gemini dari Google, dan Claude dari Anthropic.
Di sisi model terbuka (open-source), ada rumpun model Llama dari Meta, Mistral, serta model penalaran logis dari DeepSeek.
5. Apa tantangan terbesar dalam pengembangan Transformer model saat ini?
Tantangan utamanya adalah kebutuhan daya komputasi dan energi yang sangat masif. Melatih model Transformer skala besar membutuhkan ribuan GPU/TPU modern yang memakan biaya miliaran serta konsumsi listrik yang tinggi.
Selain itu, model ini masih memiliki risiko “halusinasi”, di mana AI bisa menghasilkan jawaban yang terdengar sangat meyakinkan padahal salah secara fakta.
Referensi: